Natural Transition
Our method produce natural and smooth transition between different styles of motion.
We present a novel character control framework that effectively utilizes motion diffusion probabilistic models to generate high-quality and diverse character animations, responding in real-time to a variety of dynamic user-supplied control signals. At the heart of our method lies a transformer-based Conditional Autoregressive Motion Diffusion Model (CAMDM), which takes as input the character's historical motion and can generate a range of diverse potential future motions conditioned on high-level, coarse user control. To meet the demands for diversity, controllability, and computational efficiency required by a real-time controller, we incorporate several key algorithmic designs. These include separate condition tokenization, classifier-free guidance on past motion, and heuristic future trajectory extension, all designed to address the challenges associated with taming motion diffusion probabilistic models for character control. As a result, our work represents the first model that enables real-time generation of high-quality, diverse character animations based on user interactive control, supporting animating the character in multiple styles with a single unified model. We evaluate our method on a diverse set of locomotion skills, demonstrating the merits of our method over existing character controllers.
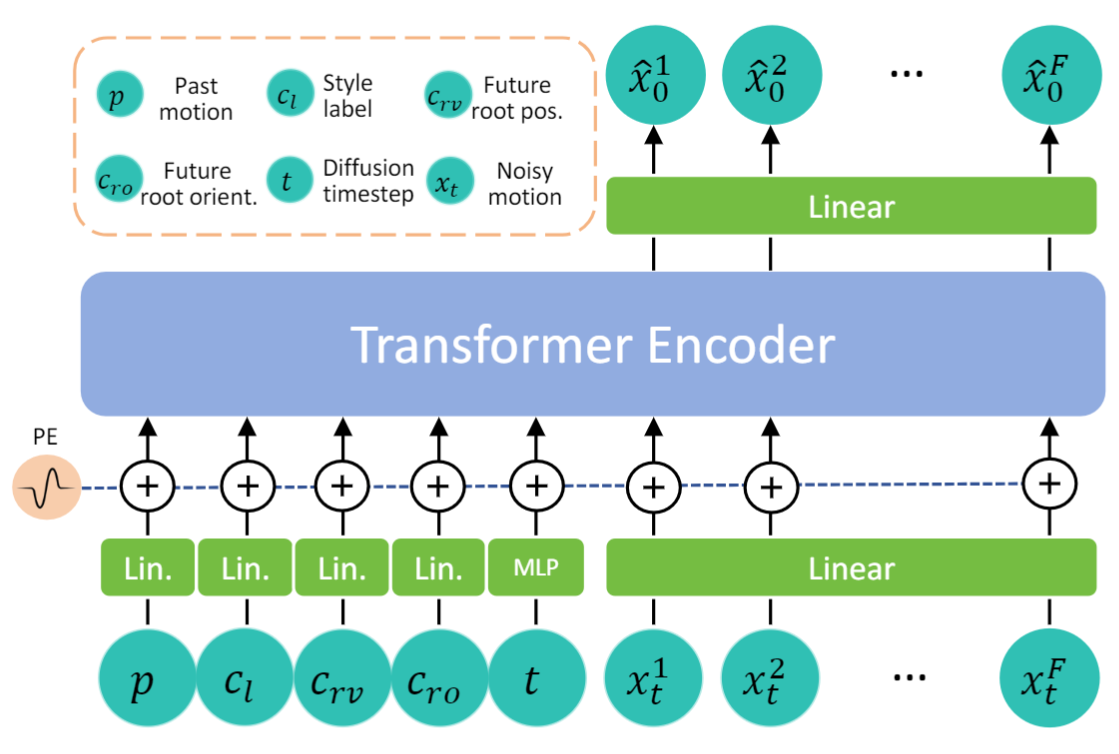
Given a large-scale locomotion dataset 100STYLE, our method first trains a Conditional Autoregressive Motion Diffusion Model (CAMDM), which takes as input the past motion of F frames of the character, and user control parameters, and then learns to capture the conditional distribution of the future motions x (of F frames). During runtime, CAMDM is applied at each frame with the on-the-fly collected character's historical poses, user control inputs, and randomly sampled Gaussian noise, and then sample from the conditional motion distribution, obtaining a sequence of realistic future postures to be displayed. The character animated using this autoregressive generation approach can exhibit coherent and diverse motions while adhering to user inputs. This is achieved because x is trained to capture all possible future motions under different conditions, yielding a wide range of plausible animations.
Our method produce natural and smooth transition between different styles of motion.
Our method can generate robust and high-quality animations based on user-applied control.
Our method is a probabilistic diffusion model, rooted in the denoising process of random noise that yields different results even when provided with different conditional inputs. The method is adept at generating diverse intra-style motions, offering a variability of movements within each style while effectively circumventing the 'mean pose' issue.
We conduct ablation studies to evaluate the effectiveness of our proposed designs.
(1) Multi-token : The system, when functioning without a multi-token design, tends to generate more artifacts and exhibits subpar control.
(2) CFG on past motion : When compared to the default CFG integrated with past motion, as utilized in our method, the application of CFG on the conditional style label results in a less desirable style transition.
For more ablation on HFTE/Diffusion steps/Backbone, etc, please refer to our paper.
w/o vs. w multi-token
w/o vs. w CFG on past motion
@inproceedings{camdm,
title={Taming Diffusion Probabilistic Models for Character Control},
author = {Chen, Rui and Shi, Mingyi and Huang, Shaoli and Tan, Ping and Komura, Taku and Chen, Xuelin},
year = {2024},
publisher = {Association for Computing Machinery},
address = {New York, NY, USA},
url = {https://doi.org/10.1145/3641519.3657440},
doi = {10.1145/3641519.3657440},
booktitle = {ACM SIGGRAPH 2024 Conference Papers},
keywords = {Character control, character animation, diffusion models},
location = {Denver, CO, USA},
series = {SIGGRAPH '24}
}